
Thế hệ tăng cường thu hồi (RAG) ban đầu được đề xuất vào năm 2020 như một phương pháp tiếp cận toàn diện kết hợp một bộ thu hồi được đào tạo trước và một máy phát điện được đào tạo trước. Vào thời điểm đó, mục tiêu chính của nó là cải thiện hiệu suất thông qua việc tinh chỉnh mô hình.
Việc phát hành ChatGPT vào tháng 12 năm 2022 đánh dấu bước ngoặt quan trọng đối với RAG . Kể từ đó, RAG tập trung nhiều hơn vào việc tận dụng khả năng lý luận của các mô hình ngôn ngữ lớn (LLM) để đạt được kết quả tạo ra tốt hơn bằng cách kết hợp kiến thức bên ngoài.
Công nghệ RAG loại bỏ nhu cầu các nhà phát triển phải đào tạo lại toàn bộ mô hình quy mô lớn cho mọi tác vụ cụ thể. Thay vào đó, họ có thể chỉ cần kết nối các cơ sở kiến thức có liên quan để cung cấp thêm thông tin đầu vào cho mô hình, nâng cao độ chính xác của câu trả lời.
Bài viết này cung cấp phần giới thiệu ngắn gọn về khái niệm, mục đích và đặc điểm của RAG.
Retrieval Augmented Generation (RAG) là gì?
Retrieval Augmented Generation (RAG) [1] là quá trình tăng cường các mô hình ngôn ngữ lớn (LLM) bằng cách kết hợp thông tin bổ sung từ các nguồn kiến thức bên ngoài. Điều này cho phép LLM tạo ra các câu trả lời chính xác hơn và có nhận thức về ngữ cảnh, đồng thời cũng làm giảm ảo giác.
Khi trả lời câu hỏi hoặc tạo văn bản, thông tin có liên quan ban đầu được lấy từ các cơ sở kiến thức hiện có hoặc một số lượng lớn tài liệu. Sau đó, câu trả lời được tạo ra bằng LLM, giúp cải thiện chất lượng phản hồi bằng cách kết hợp thông tin đã lấy được này, thay vì chỉ dựa vào LLM để tạo ra nó.
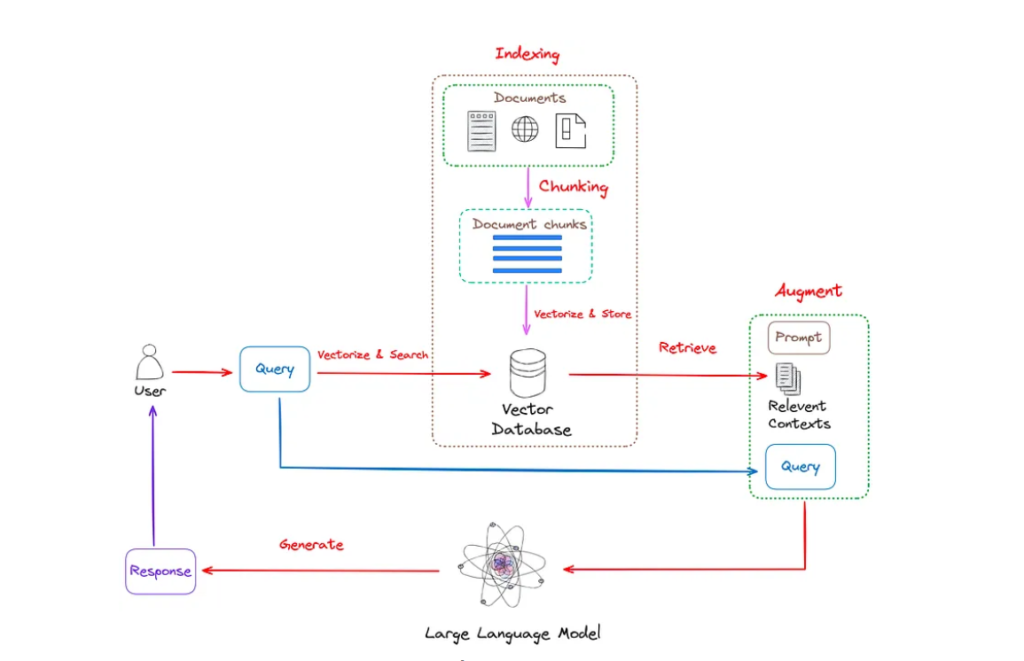
Quy trình làm việc điển hình của RAG được minh họa trong Hình 1.
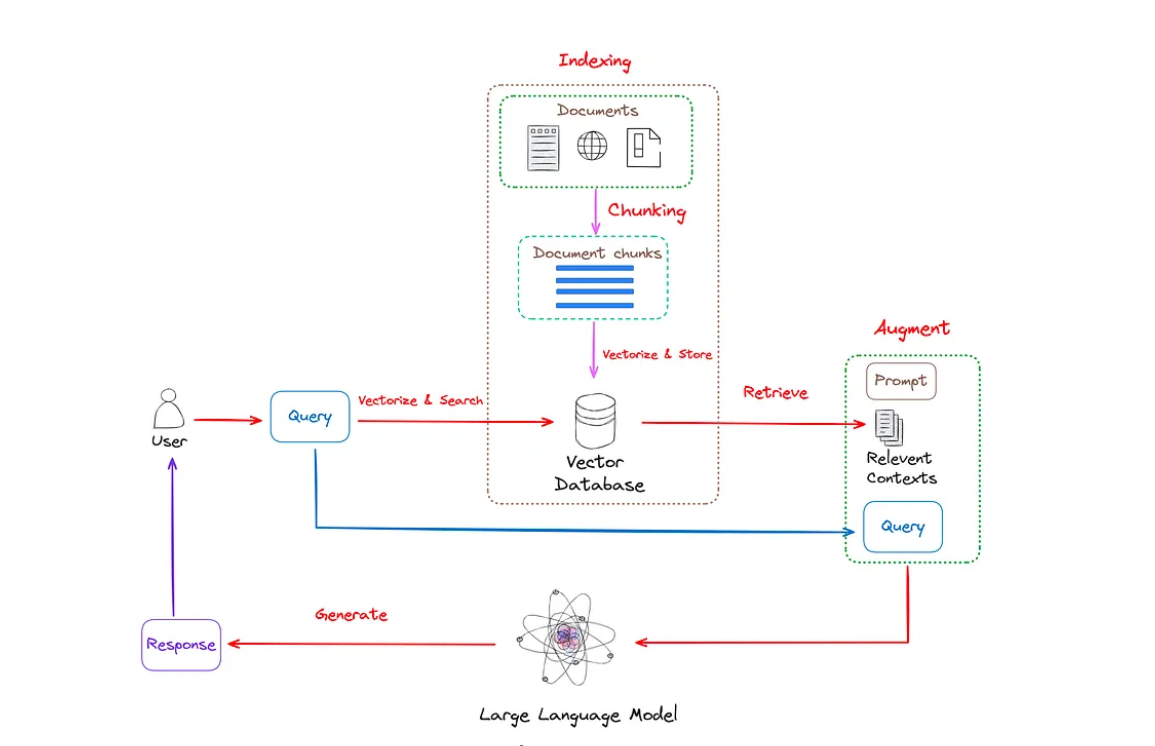
Hình 1: Quy trình làm việc điển hình của RAG. Hình ảnh của tác giả.
Như thể hiện trong Hình 1, RAG chủ yếu bao gồm các bước sau:
- Lập chỉ mục : Quá trình lập chỉ mục là bước khởi đầu quan trọng được thực hiện ngoại tuyến. Quá trình này bắt đầu bằng việc dọn dẹp và trích xuất dữ liệu thô, chuyển đổi nhiều định dạng tệp khác nhau như PDF, HTML và Word thành văn bản thuần túy được chuẩn hóa. Để phù hợp với các ràng buộc ngữ cảnh của mô hình ngôn ngữ, các văn bản này được chia thành các phần nhỏ hơn và dễ quản lý hơn, một quá trình được gọi là phân đoạn. Các phần này sau đó được chuyển đổi thành các biểu diễn vectơ bằng cách sử dụng các mô hình nhúng. Cuối cùng, một chỉ mục được tạo ra để lưu trữ các phần văn bản này và các nhúng vectơ của chúng dưới dạng các cặp khóa-giá trị, cho phép khả năng tìm kiếm hiệu quả và có thể mở rộng.
- Truy xuất : Truy vấn của người dùng được sử dụng để truy xuất ngữ cảnh có liên quan từ các nguồn kiến thức bên ngoài. Để thực hiện điều này, truy vấn của người dùng được xử lý bởi một mô hình mã hóa, mô hình này tạo ra các nhúng có liên quan về mặt ngữ nghĩa. Sau đó, tìm kiếm tương tự được thực hiện trên cơ sở dữ liệu vectơ để truy xuất k đối tượng dữ liệu gần nhất.
- Tạo : Truy vấn của người dùng và ngữ cảnh bổ sung được lấy được sẽ được điền vào mẫu nhắc nhở. Cuối cùng, lời nhắc tăng cường từ bước lấy lại sẽ được nhập vào LLM.
Tại sao chúng ta cần RAG?
Tại sao chúng ta vẫn cần RAG khi chúng ta đã có LLM? Lý do rất đơn giản: LLM không thể giải quyết được những vấn đề mà RAG có thể giải quyết. Những vấn đề này bao gồm:
- Vấn đề ảo giác mô hình : Việc tạo văn bản trong LLM dựa trên xác suất. Nếu không có đủ sự hỗ trợ thực tế, nó có thể tạo ra nội dung có vẻ nghiêm túc nhưng thiếu tính mạch lạc.
- Vấn đề về tính kịp thời : Kích thước tham số của LLM càng lớn thì chi phí đào tạo càng cao và thời gian cần thiết càng dài. Do đó, dữ liệu nhạy cảm với thời gian có thể không được đưa vào đào tạo kịp thời, dẫn đến mô hình không thể trả lời trực tiếp các câu hỏi nhạy cảm với thời gian.
- Vấn đề bảo mật dữ liệu : LLM chung không có quyền truy cập vào dữ liệu nội bộ của doanh nghiệp hoặc dữ liệu riêng tư của người dùng. Để đảm bảo bảo mật dữ liệu khi sử dụng LLM, một giải pháp tốt là lưu trữ dữ liệu cục bộ và thực hiện tất cả các phép tính dữ liệu cục bộ. LLM đám mây chỉ phục vụ mục đích tóm tắt thông tin.
- Vấn đề ràng buộc trả lời : RAG cung cấp nhiều quyền kiểm soát hơn đối với việc tạo LLM. Ví dụ, khi một câu hỏi liên quan đến nhiều điểm kiến thức, các manh mối thu được thông qua RAG có thể được sử dụng để giới hạn ranh giới của việc tạo LLM.
Đặc điểm của RAG là gì?
RAG sở hữu những đặc điểm sau đây, cho phép giải quyết hiệu quả các vấn đề đã nêu:
(1) Khả năng mở rộng: RAG làm giảm quy mô mô hình và chi phí đào tạo, đồng thời tạo điều kiện mở rộng kiến thức nhanh chóng.
(2) Độ chính xác: Mô hình cung cấp câu trả lời dựa trên sự thật, giảm thiểu tối đa hiện tượng ảo tưởng.
(3) Khả năng kiểm soát: RAG cho phép cập nhật kiến thức và tùy chỉnh.
(4) Khả năng giải thích: Thông tin có liên quan thu được đóng vai trò là tài liệu tham khảo cho các dự đoán của mô hình.
(5) Tính linh hoạt: RAG có thể được tinh chỉnh và tùy chỉnh cho nhiều nhiệm vụ khác nhau như QA, Tóm tắt, Đối thoại, v.v.
Phần kết luận
Về mặt hình ảnh, RAG có thể được ví như kỳ thi mở sách cho LLM. Tương tự như kỳ thi mở sách, sinh viên được phép mang theo tài liệu tham khảo mà họ có thể tham khảo để tìm thông tin có liên quan nhằm trả lời câu hỏi.