

3 Kỹ thuật tìm kiếm tài liệu nâng cao để cải thiện hệ thống RAG
Bạn có bao giờ nhận thấy rằng các tài liệu được hệ thống RAG truy xuất không phải lúc nào cũng phù hợp với truy vấn của người dùng không?
Đây là một hiện tượng phổ biến, đặc biệt là với các triển khai RAG có sẵn. Tài liệu có thể không có câu trả lời đầy đủ cho truy vấn, chứa thông tin thừa hoặc bao gồm các chi tiết không liên quan. Hơn nữa, thứ tự trình bày các tài liệu này có thể không nhất quán với ý định của người dùng.
Trong bài viết này, chúng ta sẽ khám phá ba kỹ thuật hiệu quả để nâng cao khả năng truy xuất tài liệu trong các ứng dụng dựa trên RAG:
- Mở rộng truy vấn
- Xếp hạng lại bộ mã hóa chéo
- Bộ điều hợp nhúng
Bằng cách kết hợp các kỹ thuật này, bạn có thể tìm được nhiều tài liệu có liên quan hơn, phù hợp hơn với truy vấn của người dùng, do đó tăng tác động của câu trả lời được tạo ra.
Chúng ta hãy cùng xem nhé.
Nếu bạn quan tâm đến nội dung ML, hướng dẫn chi tiết và mẹo thực tế từ ngành, hãy theo dõi bản tin của tôi . Bản tin này có tên là The Tech Buffet.
Buffet công nghệ
Bản tin về học máy và lập trình thực tế. Thông tin chi tiết hàng tuần để vận chuyển sản phẩm của bạn nhanh hơn.
1. Mở rộng truy vấn
Mở rộng truy vấn đề cập đến một tập hợp các kỹ thuật diễn đạt lại truy vấn ban đầu.
Bài viết này sẽ thảo luận về hai phương pháp phổ biến và dễ thực hiện.
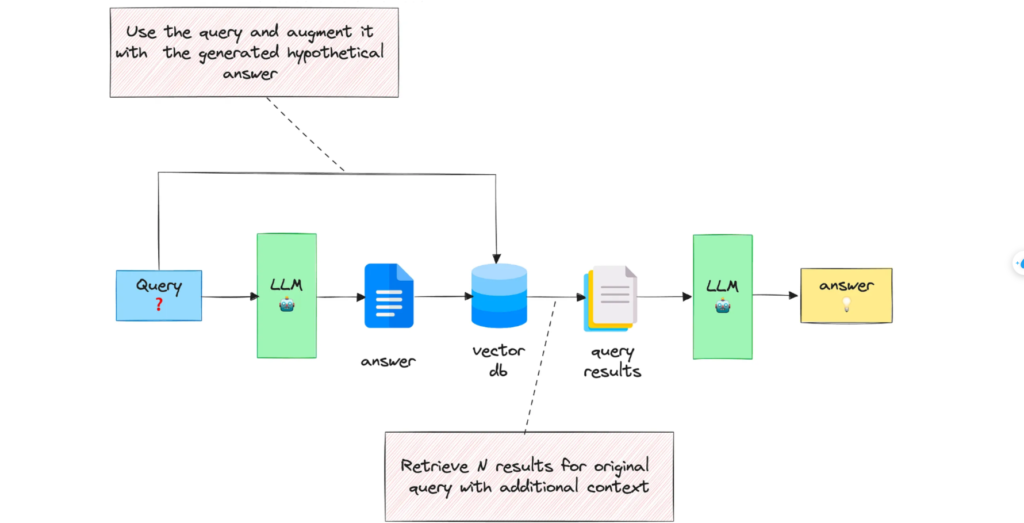
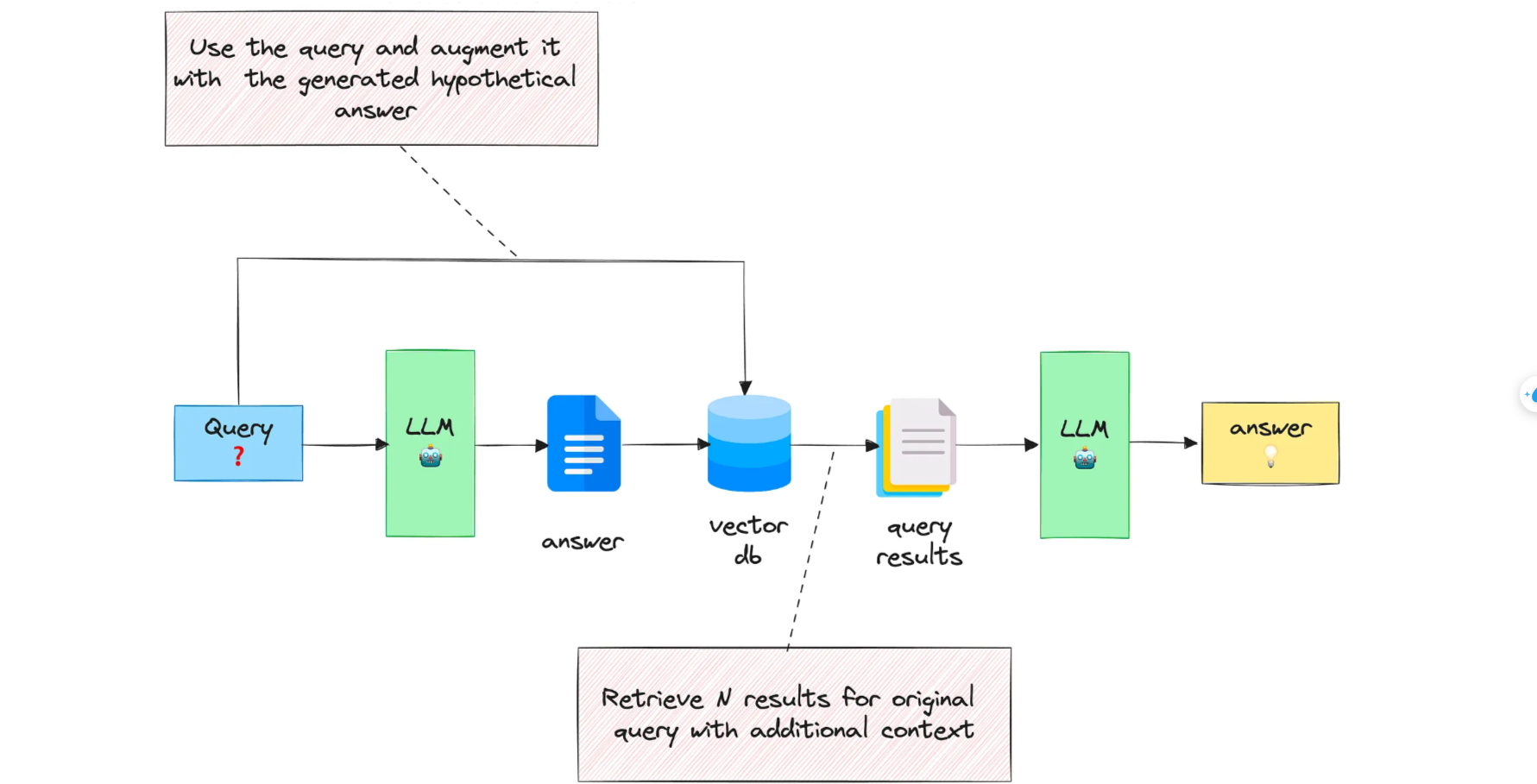
Mở rộng truy vấn với câu trả lời được tạo
Với truy vấn đầu vào, phương pháp này trước tiên sẽ hướng dẫn LLM cung cấp câu trả lời giả định, bất kể tính chính xác của câu trả lời đó.
Sau đó, truy vấn và câu trả lời được tạo ra sẽ được kết hợp trong một lời nhắc và gửi đến hệ thống tìm kiếm.
Kỹ thuật này hoạt động rất tốt . Hãy xem những phát hiện của bài báo này để tìm hiểu thêm về nó.
Cơ sở lý luận đằng sau phương pháp này là chúng ta muốn lấy các tài liệu trông giống câu trả lời hơn. Tính chính xác của câu trả lời giả định không quan trọng lắm vì điều chúng ta quan tâm là cấu trúc và cách diễn đạt của nó.
Bạn có thể coi câu trả lời giả định như một khuôn mẫu giúp xác định vùng lân cận có liên quan trong không gian nhúng.
Sau đây là ví dụ về lời nhắc tôi đã sử dụng để bổ sung cho truy vấn được gửi đến RAG để trả lời các câu hỏi về báo cáo tài chính. Bạn là trợ lý nghiên cứu tài chính chuyên nghiệp hữu ích. Cung cấp câu trả lời mẫu cho câu hỏi đã cho, có thể tìm thấy trong tài liệu như báo cáo thường niên.
Mở rộng truy vấn với nhiều câu hỏi liên quan
Phương pháp thứ hai này hướng dẫn LLM tạo N câu hỏi liên quan đến truy vấn ban đầu và sau đó gửi tất cả chúng (+ truy vấn ban đầu) đến hệ thống truy xuất.
Bằng cách này, nhiều tài liệu hơn sẽ được lấy từ vectorstore. Tuy nhiên, một số trong số chúng sẽ là bản sao, đó là lý do tại sao bạn cần thực hiện hậu xử lý để xóa chúng.
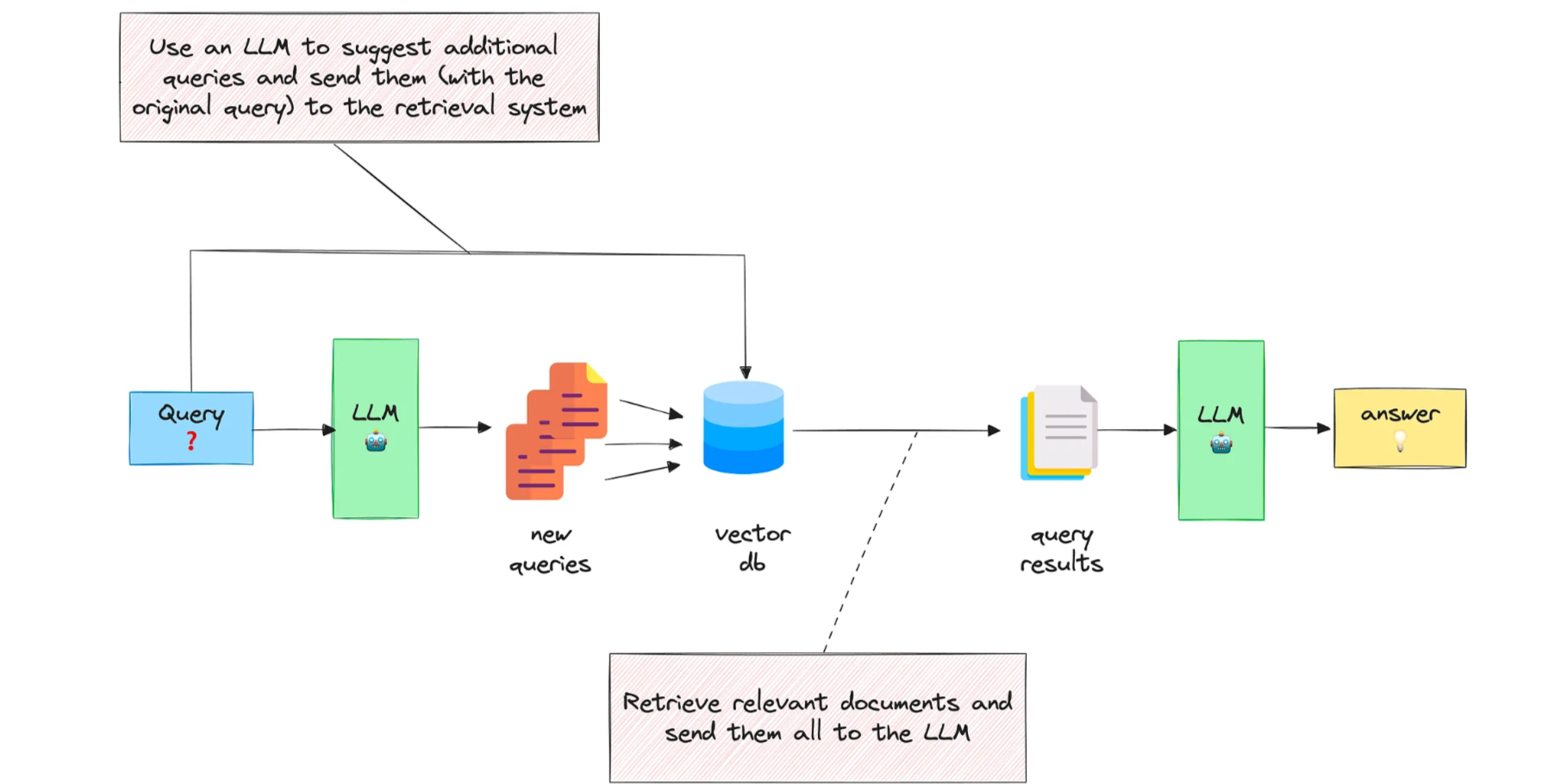
Ý tưởng đằng sau phương pháp này là bạn mở rộng truy vấn ban đầu có thể chưa đầy đủ hoặc mơ hồ và kết hợp các khía cạnh liên quan có thể có liên quan và bổ sung cho nhau.
Sau đây là lời nhắc tôi dùng để tạo ra các câu hỏi liên quan:
- Bạn là trợ lý nghiên cứu tài chính chuyên nghiệp hữu ích.
- Người dùng của bạn đang đặt câu hỏi về báo cáo thường niên.
- Đề xuất tối đa năm câu hỏi liên quan bổ sung để giúp họ
- tìm thông tin họ cần, cho câu hỏi được cung cấp.
- Chỉ đề xuất các câu hỏi ngắn không có câu ghép.
- Đề xuất nhiều câu hỏi bao gồm các khía cạnh khác nhau của chủ đề.
- Đảm bảo rằng chúng là những câu hỏi hoàn chỉnh và liên quan đến câu hỏi gốc.
- Đưa ra một câu hỏi trên mỗi dòng. Không đánh số các câu hỏi.
Nhược điểm của phương pháp này là chúng ta sẽ phải xử lý nhiều tài liệu hơn, khiến LLM không thể đưa ra câu trả lời hữu ích.
Đó chính là lúc việc xếp hạng lại phát huy tác dụng.
Để tìm hiểu thêm về các kỹ thuật mở rộng truy vấn khác nhau, hãy tham khảo bài viết này của Google.
2. Xếp hạng lại bộ mã hóa chéo 📊
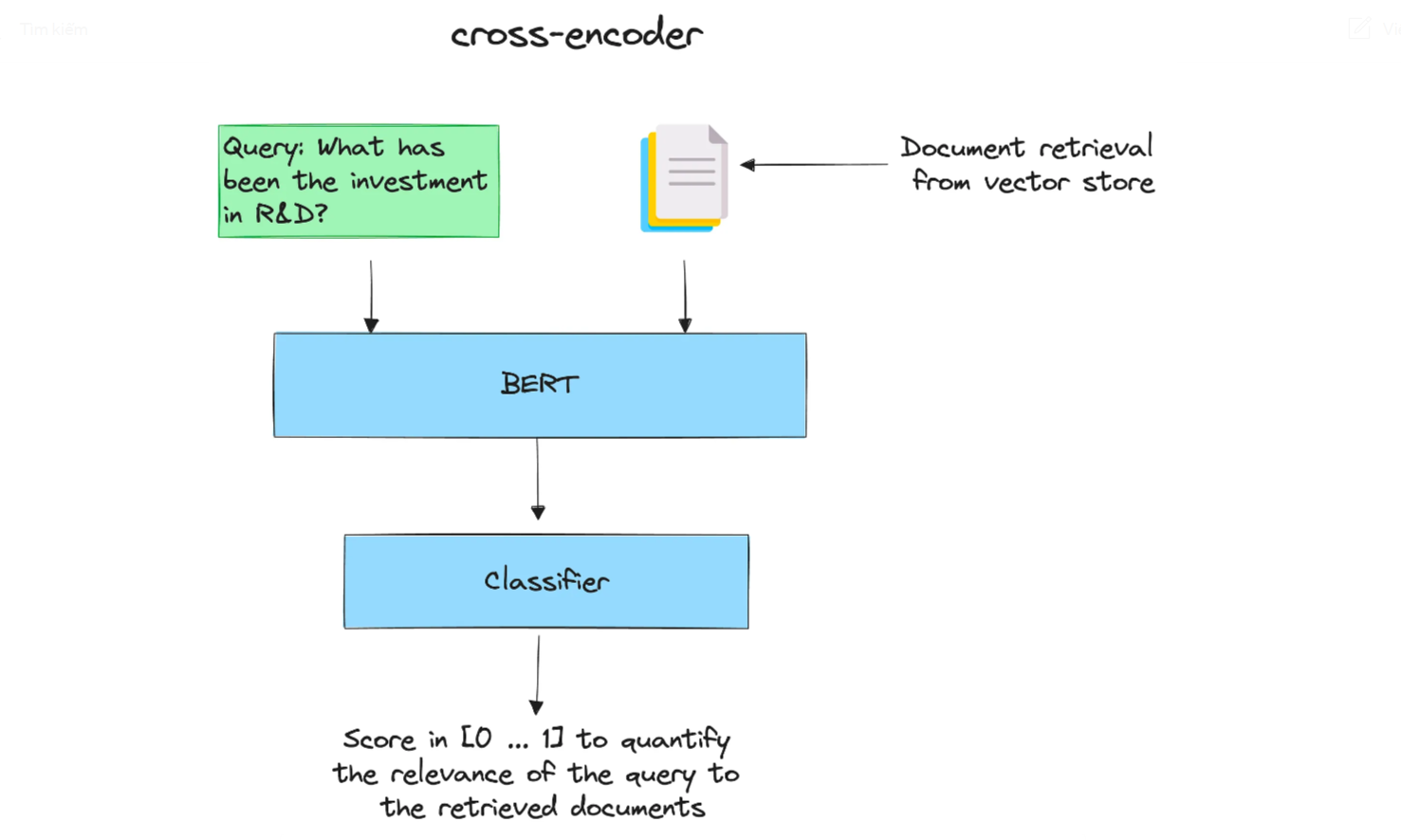
Phương pháp này xếp hạng lại các tài liệu đã thu thập được theo điểm số định lượng mức độ liên quan của chúng với truy vấn đầu vào.
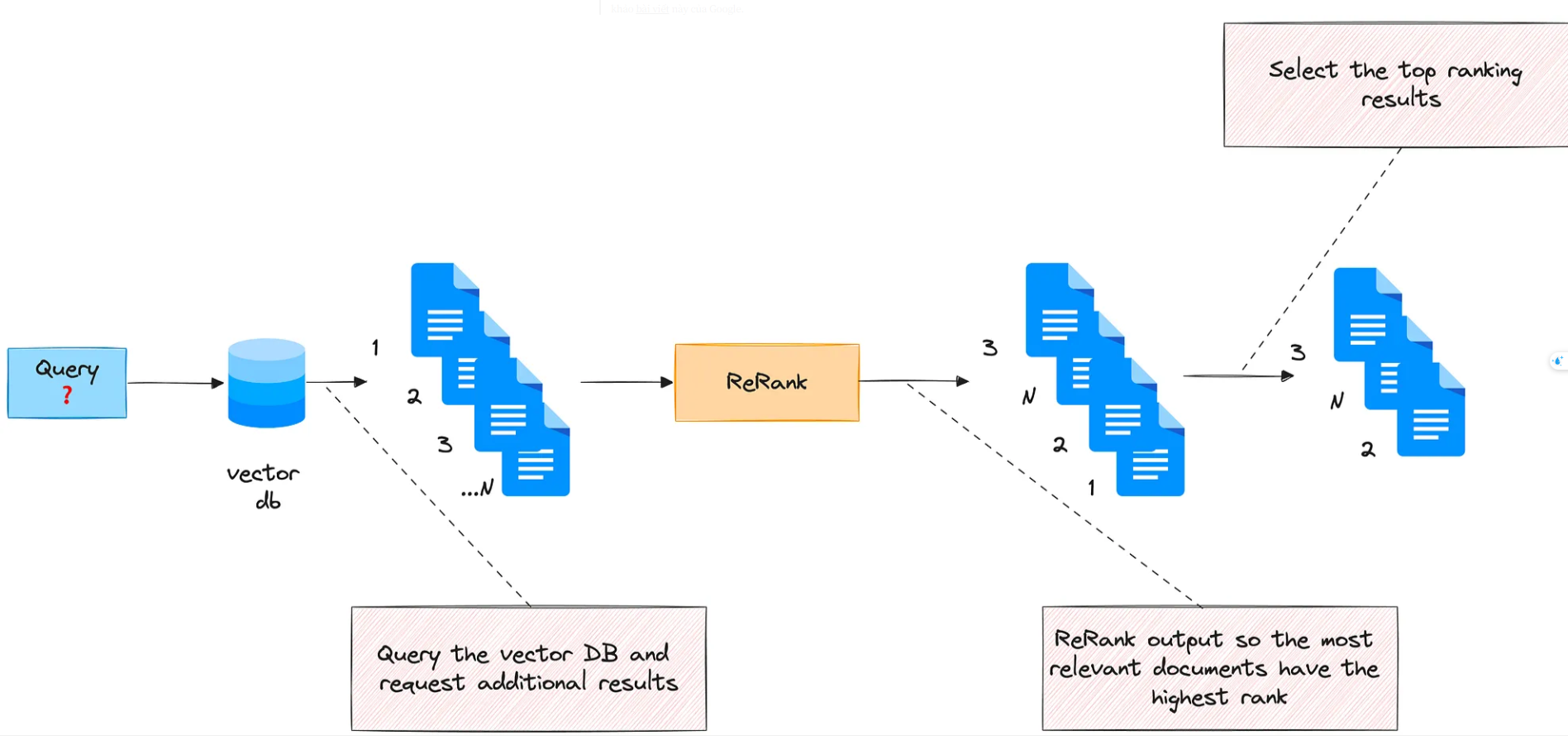
Để tính điểm này, chúng tôi sẽ sử dụng bộ mã hóa chéo . Cross-encoder là một mạng nơ-ron sâu xử lý hai chuỗi đầu vào cùng nhau như một đầu vào duy nhất. Điều này cho phép mô hình so sánh và đối chiếu trực tiếp các đầu vào, hiểu mối quan hệ của chúng theo cách tích hợp và sắc thái hơn.
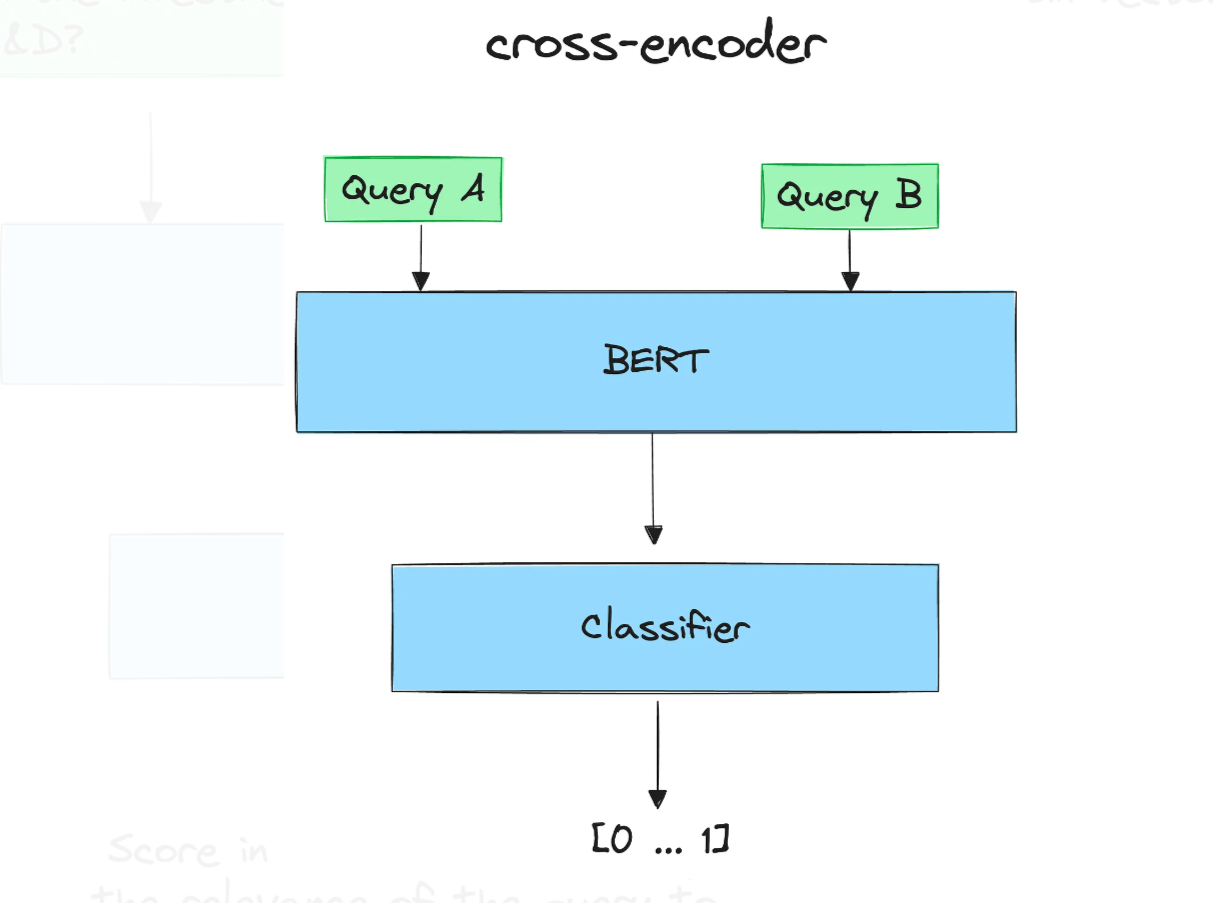
Cross-encoder có thể được sử dụng để Truy xuất thông tin: đưa ra một truy vấn, mã hóa nó với tất cả các tài liệu đã truy xuất. Sau đó, sắp xếp chúng theo thứ tự giảm dần. Các tài liệu có điểm cao là những tài liệu có liên quan nhất.
Xem SBERT.net Retrieve & Re-rank để biết thêm chi tiết.
Sau đây là cách nhanh chóng bắt đầu xếp hạng lại bằng bộ mã hóa chéo:
- Cài đặt sentence-transformers:
pip install -U sentence-transformers
- Nhập bộ mã hóa chéo và tải nó:
from sentence_transformers import CrossEncoder
cross_encoder = CrossEncoder(“cross-encoder/ms-marco-MiniLM-L-6-v2”)
- Đánh giá từng cặp (truy vấn, tài liệu):
pairs = [[query, doc] for doc in retrieved_documents] scores = cross_encoder.predict(pairs)
print(“Scores:”) for score in scores:
print(score)
- Sắp xếp lại các tài liệu:
print(“New Ordering:”)
for o in np.argsort(scores)[::-1]:
print(o+1)
Xếp hạng lại mã hóa chéo có thể được sử dụng với việc mở rộng truy vấn: sau khi bạn tạo nhiều câu hỏi liên quan và truy xuất các tài liệu tương ứng (giả sử bạn kết thúc với M tài liệu), bạn xếp hạng lại chúng và chọn K hàng đầu (K < M).
Theo cách đó, bạn giảm kích thước ngữ cảnh trong khi chọn các phần quan trọng nhất.
Ở phần tiếp theo, chúng ta sẽ tìm hiểu sâu hơn về bộ điều hợp, một kỹ thuật mạnh mẽ nhưng dễ triển khai để mở rộng nhúng sao cho phù hợp hơn với nhiệm vụ của người dùng.
3. Nhúng bộ điều hợp
Phương pháp này tận dụng phản hồi của người dùng về mức độ liên quan của các tài liệu đã thu thập để đào tạo bộ điều hợp.
Bộ điều hợp là một giải pháp thay thế nhẹ để tinh chỉnh hoàn toàn một mô hình được đào tạo trước. Hiện tại, bộ điều hợp được triển khai như các mạng nơ-ron truyền thẳng nhỏ được chèn vào giữa các lớp mô hình được đào tạo trước.
Mục tiêu cơ bản của việc đào tạo bộ điều hợp là thay đổi truy vấn nhúng để tạo ra kết quả truy xuất tốt hơn cho một tác vụ cụ thể.
Bộ điều hợp nhúng là một giai đoạn có thể được chèn sau giai đoạn nhúng và trước khi truy xuất. Hãy nghĩ về nó như một ma trận (có trọng số được đào tạo) lấy nhúng ban đầu và chia tỷ lệ.
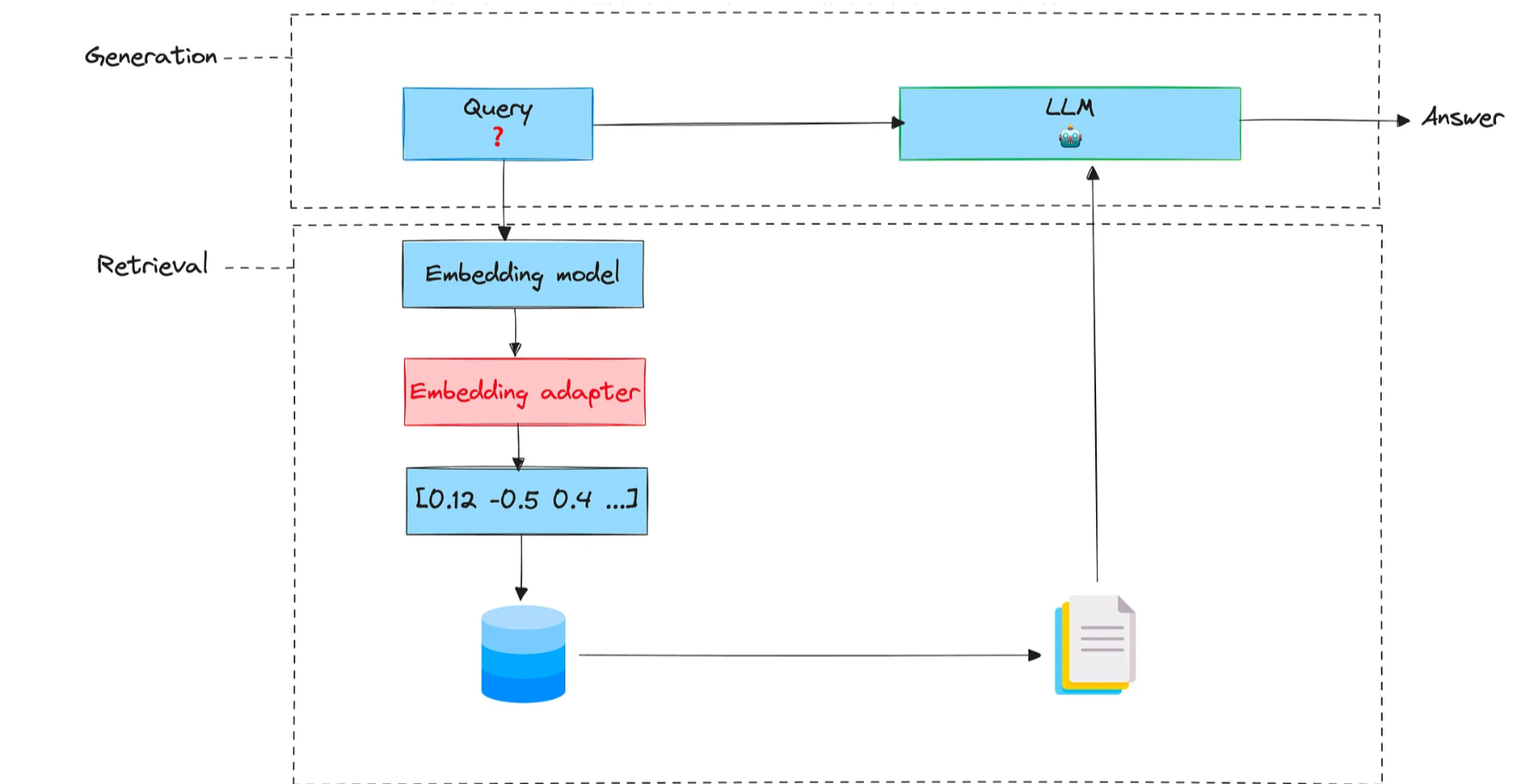
Để đào tạo một bộ điều hợp, chúng ta cần thực hiện theo các bước sau.
Chuẩn bị dữ liệu đào tạo
Để đào tạo bộ điều hợp nhúng, chúng ta cần một số dữ liệu đào tạo về tính liên quan của các tài liệu. Dữ liệu này có thể được dán nhãn thủ công hoặc được tạo bởi LLM.
Dữ liệu này phải bao gồm các cặp (truy vấn, tài liệu) cũng như nhãn tương ứng của chúng (1 nếu tài liệu có liên quan đến truy vấn, -1 nếu không).
Để đơn giản, chúng ta sẽ tạo một tập dữ liệu tổng hợp, nhưng trong bối cảnh thực tế, bạn cần tìm cách thu thập phản hồi của người dùng (ví dụ: yêu cầu người dùng đánh giá mức độ liên quan của tài liệu từ giao diện bằng 👍 và 👎)
Để tạo một số dữ liệu đào tạo, trước tiên chúng tôi tạo các câu hỏi mẫu mà nhà phân tích tài chính có thể hỏi khi phân tích báo cáo tài chính. Chúng ta hãy sử dụng LLM cho việc này:
import os
import openai
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai.api_key = os.environ[‘OPENAI_API_KEY’]
PROMPT_DATASET = “””
You are a helpful expert financial research assistant.
You help users analyze financial statements to better understand companies.
Suggest 10 to 15 short questions that are important to ask when analyzing
an annual report.
Do not output any compound questions (questions with multiple sentences
or conjunctions).
Output each question on a separate line divided by a newline.
“””
def generate_queries(model=“gpt-3.5-turbo”):
messages = [
{
“role”: “system”,
“content”: PROMPT_DATASET,
},
]
response = openai_client.chat.completions.create(
model=model,
messages=messages,
)
content = response.choices[0].message.content
content = content.split(“\n”)
return content
generated_queries = generate_queries()
for query in generated_queries:
print(query)
Sau đó, chúng tôi lấy tài liệu cho mỗi câu hỏi được tạo. Để thực hiện việc này, chúng tôi sẽ truy vấn bộ sưu tập Chroma nơi chúng tôi đã lập chỉ mục báo cáo tài chính trước đó.
results = chroma_collection.query(query_texts=generated_queries, n_results=10, include=[‘documents’, ’embeddings’])
retrieved_documents = results[‘documents’]
Chúng tôi đánh giá mức độ liên quan của từng câu hỏi với các tài liệu tương ứng. Một lần nữa, chúng tôi sẽ sử dụng LLM cho nhiệm vụ này:
PROMPT_EVALUATION = “””
You are a helpful expert financial research assistant.
You help users analyze financial statements to better understand companies.
For the given query, evaluate whether the following satement is relevant.
Output only ‘yes’ or ‘no’.
“””
def evaluate_results(query, statement, model=“gpt-3.5-turbo”):
messages = [
{
“role”: “system”,
“content”: PROMPT_EVALUATION,
},
{
“role”: “user”,
“content”: f”Query: {query}, Statement: {statement}“
}
]
response = openai_client.chat.completions.create(
model=model,
messages=messages,
max_tokens=1
)
content = response.choices[0].message.content
if content == “yes”:
return 1
return –1
Bây giờ chúng ta cấu trúc dữ liệu đào tạo thành các bộ.
Mỗi bộ sẽ chứa nhúng của truy vấn, nhúng của tài liệu và nhãn đánh giá (1, -1).
rretrieved_embeddings = results[’embeddings’] query_embeddings = embedding_function(generated_queries)
adapter_query_embeddings = [] adapter_doc_embeddings = [] adapter_labels = []
for q, query in enumerate(tqdm(generated_queries)):
for d, document in enumerate(retrieved_documents[q]):
adapter_query_embeddings.append(query_embeddings[q])
adapter_doc_embeddings.append(retrieved_embeddings[q][d])
adapter_labels.append(evaluate_results(query, document))
Khi các bộ dữ liệu được tạo, chúng tôi sẽ đưa chúng vào Bộ dữ liệu Torch để chuẩn bị cho quá trình đào tạo.
adapter_query_embeddings = torch.Tensor(np.array(adapter_query_embeddings))
adapter_doc_embeddings = torch.Tensor(np.array(adapter_doc_embeddings))
adapter_labels = torch.Tensor(np.expand_dims(np.array(adapter_labels),1))
dataset = torch.utils.data.TensorDataset(adapter_query_embeddings, adapter_doc_embeddings, adapter_labels)
Xác định một mô hình
Chúng tôi định nghĩa một hàm lấy nhúng truy vấn, nhúng tài liệu và ma trận bộ điều hợp làm đầu vào. Hàm này trước tiên nhân nhúng truy vấn với ma trận bộ điều hợp và tính toán độ tương đồng cosin giữa kết quả này và nhúng tài liệu.
def model(query_embedding, document_embedding, adaptor_matrix):
updated_query_embedding = torch.matmul(adaptor_matrix, query_embedding)
return torch.cosine_similarity(updated_query_embedding, document_embedding, dim=0)
Xác định sự mất mát
Mục tiêu của chúng tôi là giảm thiểu độ tương đồng cosin được tính toán bởi hàm trước đó. Để thực hiện điều này, chúng tôi sẽ sử dụng mất mát Lỗi bình phương trung bình (MSE) để tối ưu hóa trọng số của ma trận bộ điều hợp.
def mse_loss(query_embedding, document_embedding, adaptor_matrix, label):
return torch.nn.MSELoss()(model(query_embedding, document_embedding, adaptor_matrix), label))
Chạy ngược lan truyền:
Ở bước này, trước tiên chúng ta khởi tạo ma trận bộ điều hợp và đào tạo nó trong hơn 100 kỷ nguyên.
# Initialize the adaptor matrix
mat_size = len(adapter_query_embeddings[0])
adapter_matrix = torch.randn(mat_size, mat_size, requires_grad=True)
min_loss = float(‘inf’)
best_matrix = None
for epoch in tqdm(range(100)):
for query_embedding, document_embedding, label in dataset:
loss = mse_loss(query_embedding, document_embedding, adapter_matrix, label)
if loss < min_loss:
min_loss = loss
best_matrix = adapter_matrix.clone().detach().numpy()
loss.backward()
with torch.no_grad():
adapter_matrix -= 0.01 * adapter_matrix.grad
adapter_matrix.grad.zero_()
Sau khi quá trình đào tạo hoàn tất, bộ điều hợp có thể được sử dụng để mở rộng nhúng ban đầu và thích ứng với tác vụ của người dùng.
Bây giờ tất cả những gì bạn cần là lấy đầu ra nhúng ban đầu và nhân nó với ma trận bộ điều hợp trước khi đưa vào hệ thống truy xuất.
test_vector = torch.ones((mat_size,1))
scaled_vector = np.matmul(best_matrix, test_vector).numpy()
test_vector.shape
# torch.Size([384, 1])
scaled_vector.shape
# (384, 1)
best_matrix.shape
# (384, 384)
Cảm ơn bạn đã đọc
Các kỹ thuật truy xuất mà chúng tôi đề cập giúp cải thiện tính liên quan của tài liệu.
Tuy nhiên, vẫn đang có những nghiên cứu đang được tiến hành trong lĩnh vực này và các phương pháp khác hiện đang được đánh giá và khám phá. Ví dụ,
- Tinh chỉnh mô hình nhúng bằng cách sử dụng dữ liệu phản hồi thực tế
- Tinh chỉnh LLM trực tiếp để tối đa hóa sức mạnh truy xuất của nó ( RA-DIT: Điều chỉnh hướng dẫn kép tăng cường truy xuất )
- Khám phá các bộ điều hợp nhúng phức tạp hơn bằng cách sử dụng mạng nơ-ron sâu thay vì ma trận
- Kỹ thuật phân đoạn sâu và thông minh
Chúng ta sẽ nói thêm về chúng sau.