
Chia các tài liệu lớn thành các phần nhỏ hơn là một yếu tố thiết yếu nhưng quan trọng ảnh hưởng đến hiệu suất của các hệ thống Retrieval Augmented Generation (RAG). Các khuôn khổ để phát triển các hệ thống RAG thường cung cấp một số tùy chọn để lựa chọn. Trong bài viết này, tôi muốn giới thiệu một tùy chọn mới cố gắng nhận ra sự thay đổi chủ đề với sự trợ giúp của các câu nhúng khi chia nhỏ các tài liệu để thực hiện việc chia nhỏ tại các điểm này. Điều này đặt nền tảng rằng trong bước nhúng của hệ thống RAG, có thể tìm thấy các vectơ cho các phần văn bản mã hóa một chủ đề và không phải là hỗn hợp của nhiều chủ đề. Chúng tôi đã trình bày phương pháp này trong một bài báo trong bối cảnh mô hình hóa chủ đề, nhưng nó cũng phù hợp để sử dụng trong các hệ thống RAG.
Hệ thống RAG
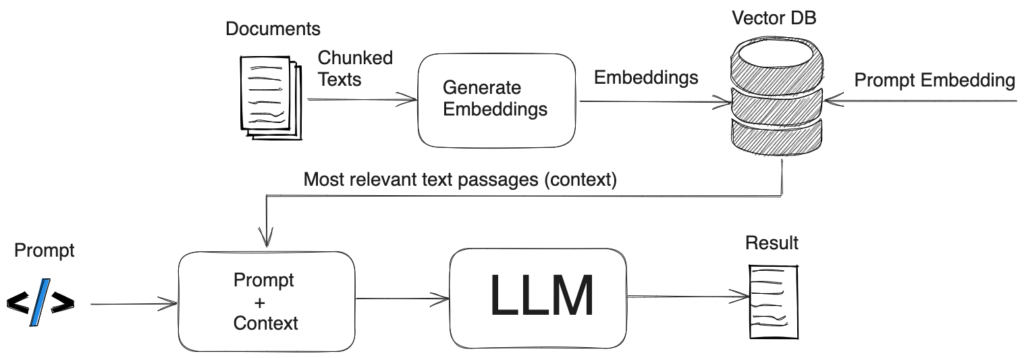
Hệ thống Retrieval-Augmented Generation (RAG) là một mô hình học máy kết hợp các phương pháp tiếp cận dựa trên retrieval và dựa trên generation để cải thiện chất lượng và tính liên quan của đầu ra. Đầu tiên, nó sẽ truy xuất các tài liệu hoặc thông tin có liên quan từ một tập dữ liệu lớn dựa trên truy vấn đầu vào. Sau đó, nó sử dụng một mô hình generation, chẳng hạn như mô hình ngôn ngữ dựa trên transformer, để tạo ra phản hồi hoặc nội dung mạch lạc và phù hợp với ngữ cảnh bằng cách sử dụng thông tin đã truy xuất. Phương pháp tiếp cận kết hợp này nâng cao khả năng cung cấp phản hồi chính xác và nhiều thông tin của mô hình, đặc biệt là trong các tác vụ phức tạp hoặc đòi hỏi nhiều kiến thức.
Các tùy chọn chia tách khác
Trước khi chúng ta xem xét quy trình chi tiết hơn, tôi muốn trình bày một số tùy chọn tiêu chuẩn khác để phân tách tài liệu. Tôi sẽ sử dụng khuôn khổ Langchain được sử dụng rộng rãi để đưa ra các ví dụ.
LangChain
Bộ sản phẩm của LangChain hỗ trợ các nhà phát triển trong từng bước của hành trình phát triển.
LangChain là một khuôn khổ mạnh mẽ được thiết kế để hỗ trợ nhiều tác vụ xử lý ngôn ngữ tự nhiên (NLP), chủ yếu tập trung vào việc áp dụng các mô hình ngôn ngữ lớn. Một trong những chức năng thiết yếu của nó là phân chia tài liệu, cho phép người dùng chia nhỏ các tài liệu lớn thành các phần nhỏ hơn, dễ quản lý hơn. Dưới đây là các tính năng chính và ví dụ về phân chia tài liệu trong LangChain:
Các tính năng chính của việc chia tách tài liệu trong LangChain
- Recursive Character Text Splitter : Phương pháp này chia tách tài liệu bằng cách chia văn bản theo ký tự, đảm bảo mỗi đoạn có độ dài dưới một độ dài nhất định. Điều này đặc biệt hữu ích cho các tài liệu có ngắt đoạn hoặc ngắt câu tự nhiên.
- Token Splitter : Phương pháp này chia tài liệu bằng token. Phương pháp này có lợi khi làm việc với các mô hình ngôn ngữ có giới hạn token, đảm bảo mỗi khối phù hợp với các ràng buộc của mô hình.
- Sentence Splitter : Phương pháp này chia tài liệu theo ranh giới câu. Phương pháp này lý tưởng để duy trì tính toàn vẹn ngữ cảnh của văn bản, vì các câu thường biểu diễn các ý hoàn chỉnh.
- Regex Splitter : Phương pháp này sử dụng biểu thức chính quy để xác định các điểm phân chia tùy chỉnh. Nó cung cấp tính linh hoạt cao nhất, cho phép người dùng phân chia tài liệu dựa trên các mẫu cụ thể cho trường hợp sử dụng của họ.
- Markdown Splitter : Phương pháp này được thiết kế riêng cho các tài liệu markdown. Nó chia văn bản dựa trên các thành phần cụ thể của markdown như tiêu đề, danh sách và khối mã.
Ví dụ về việc chia tách tài liệu trong LangChain
1. Recursive Character Text Splitter

2. Token Splitter

3. Sentence Splitter

4. Regex Splitter

5. Markdown Splitter

Giới thiệu một cách tiếp cận mới
Phân đoạn các tài liệu quy mô lớn thành các phần theo chủ đề mạch lạc trong phân tích nội dung số là một thách thức đáng kể. Các phương pháp truyền thống, chẳng hạn như các phương pháp được mô tả ở trên, thường không phát hiện chính xác các điểm giao thoa tinh tế khi các chủ đề thay đổi. Trong một bài báo trình bày tại Hội nghị quốc tế về Trí tuệ nhân tạo, Máy tính, Khoa học dữ liệu và Ứng dụng (ACDSA 2024), chúng tôi đề xuất một cách tiếp cận sáng tạo để giải quyết vấn đề này.
Thách thức cốt lõi
Các tài liệu lớn, chẳng hạn như các bài báo học thuật, báo cáo dài và bài viết chi tiết, rất phức tạp và chứa nhiều chủ đề. Các kỹ thuật phân đoạn thông thường, từ các phương pháp dựa trên quy tắc đơn giản đến các thuật toán học máy tiên tiến, đều gặp khó khăn trong việc xác định các điểm chính xác của quá trình chuyển đổi chủ đề. Các phương pháp này thường bỏ lỡ các quá trình chuyển đổi tinh tế hoặc xác định sai chúng, dẫn đến các phần bị phân mảnh hoặc chồng chéo.
Phương pháp của chúng tôi tận dụng sức mạnh của việc nhúng câu để tăng cường quá trình phân đoạn.Phương pháp này đo lường định lượng mức độ tương đồng của chúng bằng cách sử dụng Sentence-BERT (SBERT) để tạo nhúng cho từng câu. Khi chủ đề thay đổi, các nhúng này phản ánh những thay đổi trong không gian vectơ, chỉ ra các chuyển đổi chủ đề tiềm năng.
Hãy xem xét từng bước của phương pháp này:
1. Sử dụng nhúng câu
Tạo nhúng:
- Phương pháp này sử dụng Sentence-BERT (SBERT) để tạo nhúng cho từng câu. SBERT tạo ra các biểu diễn vectơ dày đặc của các câu bao hàm nội dung ngữ nghĩa của chúng.
- Những nhúng này sau đó được so sánh để xác định tính mạch lạc giữa các câu liên tiếp.
Tính toán độ tương đồng:
- Độ tương đồng giữa các câu được đo bằng độ tương đồng cosin hoặc các phép đo khoảng cách khác như khoảng cách Manhattan hoặc Euclid.
- Ý tưởng là các câu trong cùng một chủ đề sẽ có nội dung nhúng tương tự, trong khi các câu từ các vấn đề khác nhau sẽ có mức độ tương đồng giảm.
2. Tính Điểm Chênh Lệch
Định nghĩa tham số n:
- Một tham số n được thiết lập, chỉ định số câu cần so sánh. Ví dụ, nếu n=2, hai câu liên tiếp được so sánh với cặp tiếp theo.
- Việc lựa chọn n ảnh hưởng đến độ dài ngữ cảnh được xem xét trong quá trình so sánh, cân bằng nhu cầu nắm bắt các chuyển đổi chi tiết với hiệu quả tính toán.
Tính toán độ tương đồng Cosine:
- Đối với mỗi vị trí trong tài liệu, thuật toán sẽ trích xuất n câu trước và sau vị trí hiện tại.
- Sau đó, nó tính toán độ tương đồng cosin giữa các nhúng của các chuỗi này, được gọi là ‘điểm khoảng cách’.
- Những điểm chênh lệch này được lưu trữ trong một danh sách để xử lý thêm.
Ví dụ về Điểm số chênh lệch / Hình ảnh của tác giả
3. Làm mịn
Xử lý tiếng ồn:
- Điểm khoảng cách thô có thể bị nhiễu do những thay đổi nhỏ trong văn bản. Để khắc phục điều này, thuật toán làm mịn được áp dụng.
- Làm mịn bao gồm việc tính trung bình điểm số khoảng cách trong một cửa sổ được xác định bởi tham số k.
Chọn kích thước cửa sổ k:
- Kích thước cửa sổ k xác định mức độ làm mịn. Giá trị k lớn hơn dẫn đến làm mịn nhiều hơn, giảm nhiễu nhưng có khả năng bỏ lỡ các chuyển đổi tinh tế. Giá trị k nhỏ hơn giữ lại nhiều chi tiết hơn nhưng có thể gây nhiễu.
- Điểm số khoảng cách được làm mịn cung cấp dấu hiệu rõ ràng hơn về vị trí diễn ra sự chuyển đổi chủ đề.
Ví dụ về Điểm số Khoảng cách sau khi Làm mịn / Hình ảnh của tác giả
4. Phát hiện ranh giới
Xác định giá trị cực tiểu cục bộ:
- Điểm số khoảng cách được làm mịn được phân tích để xác định các điểm cực tiểu cục bộ và các điểm tiềm năng của quá trình chuyển đổi chủ đề.
- Điểm độ sâu được tính cho mỗi giá trị cực tiểu cục bộ bằng cách cộng các chênh lệch giữa giá trị cực tiểu cục bộ và các giá trị trước và sau.
Thiết lập ngưỡng c:
- Tham số ngưỡng c được sử dụng để xác định ranh giới quan trọng. Giá trị c cao hơn dẫn đến ít phân đoạn quan trọng hơn, trong khi giá trị c thấp hơn dẫn đến nhiều phân đoạn nhỏ hơn.
- Các ranh giới vượt quá điểm độ sâu trung bình hơn c lần độ lệch chuẩn được coi là điểm phân đoạn hợp lệ.
Ví dụ về Phân đoạn / Hình ảnh của tác giả
5. Phân cụm các phân đoạn
Xử lý các chủ đề lặp lại:
- Các tài liệu dài hơn có thể xem lại các chủ đề tương tự tại các điểm khác nhau. Để giải quyết vấn đề này, thuật toán nhóm các phân đoạn có nội dung tương tự.
- Điều này bao gồm việc chuyển đổi các phân đoạn thành nhúng và sử dụng các kỹ thuật nhóm để hợp nhất các phân đoạn tương tự.
Giảm sự dư thừa:
- Phân cụm giúp giảm sự trùng lặp bằng cách đảm bảo mỗi chủ đề được thể hiện duy nhất, tăng cường tính mạch lạc và độ chính xác tổng thể của phân đoạn.
Mã giả thuật toán
Tính điểm chênh lệch:
Làm mịn điểm số khoảng cách:
Phát hiện ranh giới:
- Điểm độ sâu được tính cho mỗi mức tối thiểu cục bộ.
- Ngưỡng được áp dụng bằng cách sử dụng tham số c để xác định các điểm phân đoạn quan trọng.
Hướng đi trong tương lai
Nghiên cứu nêu ra một số lĩnh vực cần nghiên cứu thêm để cải thiện phương pháp này:
- Tối ưu hóa tham số tự động: Sử dụng các kỹ thuật học máy để điều chỉnh các tham số một cách linh hoạt.
- Thử nghiệm tập dữ liệu mở rộng hơn: Kiểm tra phương pháp trên nhiều tập dữ liệu lớn, đa dạng.
- Phân đoạn theo thời gian thực: Khám phá các ứng dụng thời gian thực cho các tài liệu động.
- Cải tiến mô hình: Tích hợp các mô hình máy biến áp mới hơn.
- Phân đoạn đa ngôn ngữ: Áp dụng phương pháp này cho nhiều ngôn ngữ khác nhau bằng cách sử dụng SBERT đa ngôn ngữ.
- Phân đoạn theo thứ bậc: Nghiên cứu phân đoạn ở nhiều cấp độ để phân tích tài liệu chi tiết.
- Phát triển giao diện người dùng: Tạo các công cụ tương tác để điều chỉnh kết quả phân đoạn dễ dàng hơn.
- Tích hợp với tác vụ NLP: Kết hợp thuật toán với các tác vụ xử lý ngôn ngữ tự nhiên khác.
Phần kết luận
Phương pháp của chúng tôi trình bày một cách tiếp cận tinh vi để phân đoạn tài liệu, kết hợp các nguyên tắc truyền thống với các kỹ thuật nhúng câu tiên tiến. Bằng cách tận dụng SBERT và các kỹ thuật làm mịn và phân cụm tiên tiến, quy trình này cung cấp một giải pháp mạnh mẽ và hiệu quả để mô hình hóa chủ đề chính xác trong các tài liệu lớn.